
Converting JSON to BigQuery ARRAY and STRUCT

Senior Data Engineer • Contractor / Freelancer • GCP & AWS Certified
Earlier in 2022 BigQuery introduced native support for the JSON datatype. Previously, one would have had to store the JSON data in a string column. This new development opens the door to a lot of interesting use cases, given the widespread adoption and flexibility that this format allows.
Now, what are the trade-offs one would need to consider when choosing between storing the data using the JSON datatype versus the ARRAY and STRUCT data types commonly in BigQuery? I’ve recently come across a great blog post comparing these approaches.
My takeaway is that if you’d be willing to give up a little bit on the flexibility of JSON and are not afraid of working with nested data, this might be an interesting choice. There is value to be found here in storage and querying cost savings as well as in easiness of accessing and exploring the data stored. Again, this might vary greatly based on one’s use case, data shape and size.
In this short article, we’re going to do a practical exercise of converting a JSON-containing string / JSON data type into classical BigQuery structures: ARRAYS and STRUCTS.
We’re going to transform this:
into this:
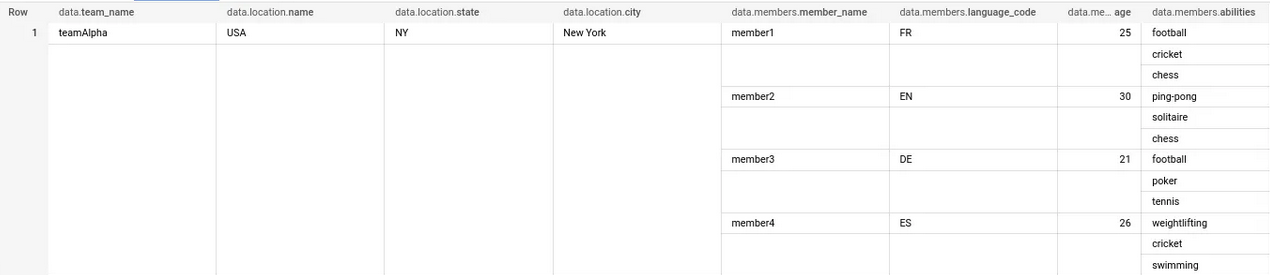
For that, we’ll need to:
extract the data using JSON_VALUE and JSON_EXTRACT ARRAY (with UNNEST)
create a STRUCT for each JSON object and an ARRAY for each JSON array, and do so from outside to the inside
nest the data, imitating the source and aliasing appropriately
cast the attributes to the appropriate BigQuery datatype
Notice how above, when extracting an array member (ability) from an attribute inside a struct that is inside another array (members), we’re using the unnested member as the input to the JSON_VALUE function
FROM UNNEST(JSON_EXTRACT_ARRAY(jsondata, "$.members")) AS member
FROM UNNEST(JSON_EXTRACT_ARRAY(member, '$.abilities')) AS ability
If we were to save our results to a table, the schema would look as follows:

Under the right conditions — the absence of a schema drift in the source, volumes big enough to be worth the hassle, multiple nested attributes with arrays, and users trained to interact with nested data — this structure would be more efficient for storage and querying while also allowing for more discoverability of the data. One would not need to study the JSON schema anymore to understand the shape of the data, a simple look at the above schema would suffice.
Thanks for reading!
Found it useful? Subscribe to my Analytics newsletter at notjustsql.com.
Enjoyed this? Here are some related articles you might find useful:




