
Loading data from Google Cloud Storage into BigQuery using Cloud Workflows
Senior Data Engineer • Contractor / Freelancer • GCP & AWS Certified
Google Cloud Workflows is a serverless orchestration platform that allows us to combine services into repeatable and observable sets of actions, connecting typically other GCP services. These are called, you guessed it, workflows.
While working as a Data Engineer and extensively using Apache Airflow (and its GCP implementation called Composer), I was a little skeptical in the beginning about what it is offering but came to appreciate its straightforwardness and simplicity.
In this quick exercise, we’re going to illustrate a simple use case — loading a CSV file from Google Cloud Storage into BigQuery.
Preparation work
Let’s set up the appropriate accounts and permissions. For this job, we’ve created a service account and assigned it the role “Big Query Job User”

Project roles for our service account
We’re also granted permission to the same service account to the Google Cloud Storage bucket from where we intend to load data from.

Bucket permissions for the service account
Next, we need to create a destination BigQuery dataset and provide the service account “Big Query Data Editor” role on it. Note that the dataset needs to be in the same GCP region (or multi-region) as the bucket load our data into.
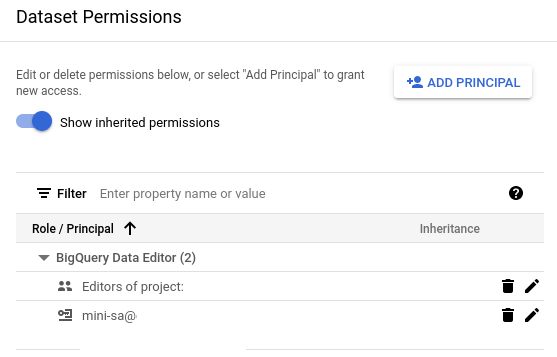
BigQuery Destination dataset permissions
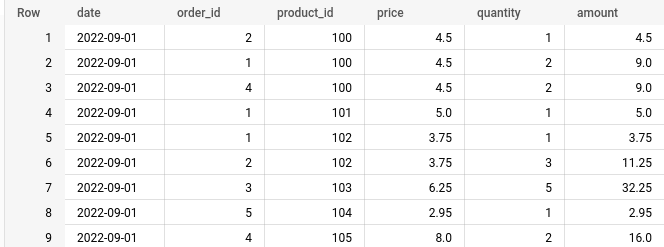
Now, let’s have a look at our file — a regular comma-delimited CSV, with the first row being the header row.
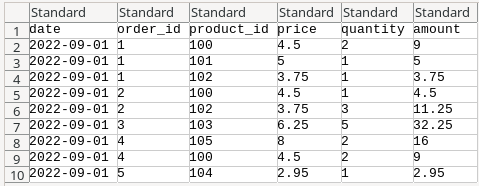
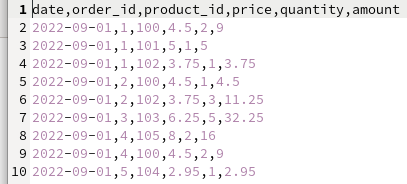
By our legend, this file follows the below naming convention, with the first part being the date of the sale.
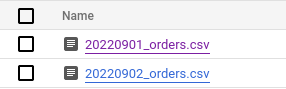
All good, now let’s get to the workflow itself.
Creating the workflow
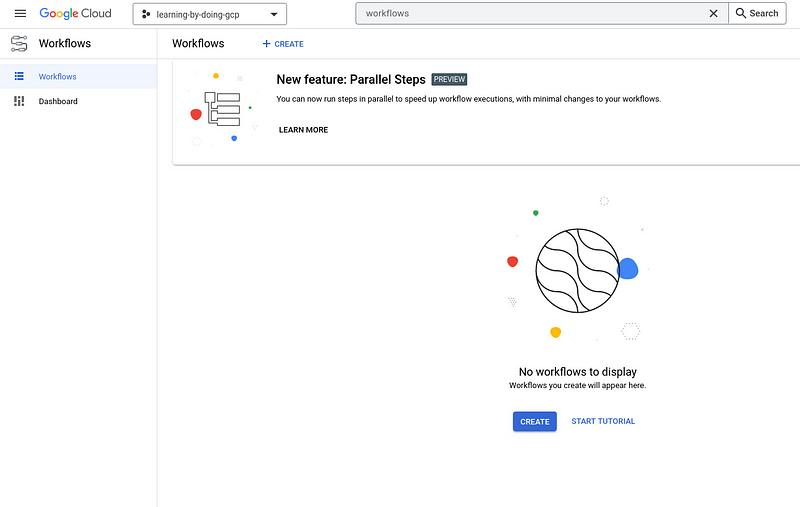
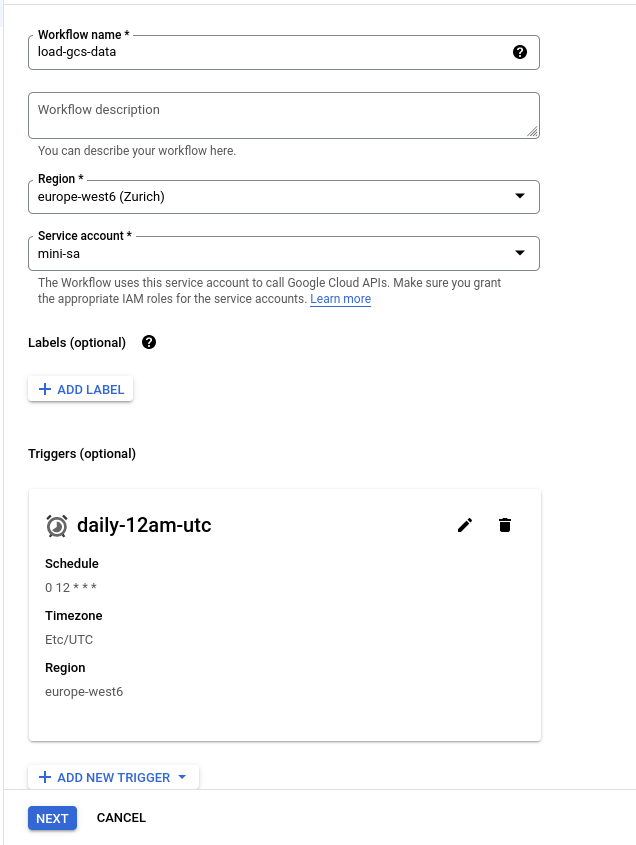
In the dialog box we are presented, we give our workflow a name, pick the region and a service account (same as the one that we granted permissions above) to run the workflow under.
If, let’s say, we’d like to read the file every day, that is — run the workflow on a particular schedule, we can create a Cloud Scheduler Trigger. This would automatically run the workflows at the given cadence.
Note that the project-level role “Workflows Invoker” needs to be attached to the service account triggering the Workflow.
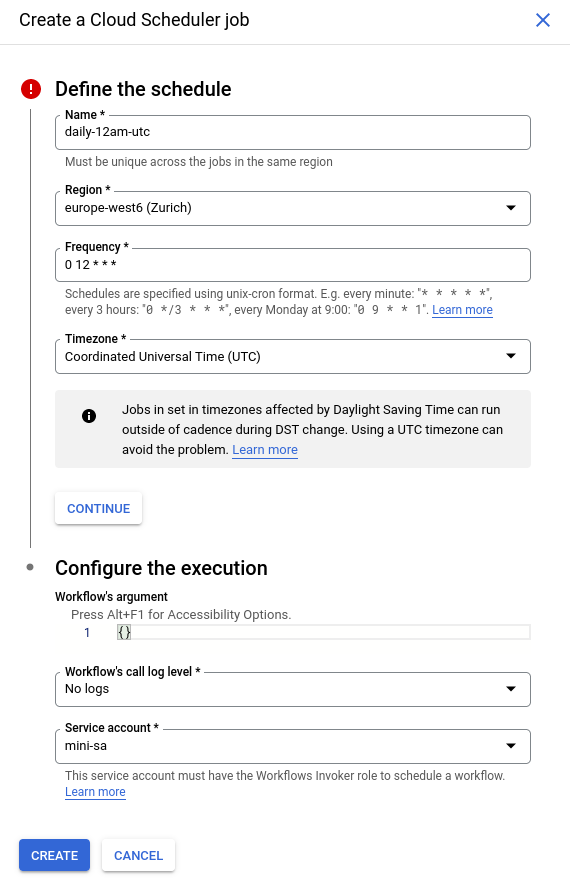
A workflow with a trigger would look as follows
Creating the steps
We now have the Workflow development window, where we can write the definition for our workflow in YAML-esque syntax. If you aren’t familiar with Workflow syntax, a good place to start is the Workflows tutorials page. Also, note the pane on the right side, illustrating our control flow
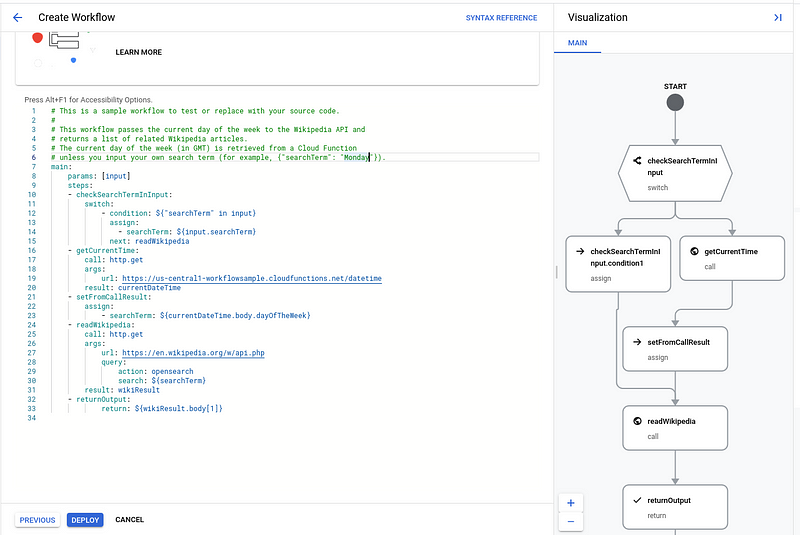
We now need the build the workflow logic. For this exercise, we’ll need to check the configuration options we can set up for the BigQuery job, documented at the following link
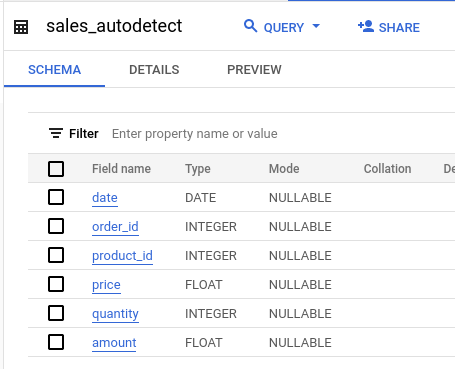
The easiest approach is to try to load data while using the schema auto-detect. Note the autodetect: true part in the load configuration.
The below code will:
declare a resultsList List where we would accumulate job results
create a BigQuery insert job with a set of provided arguments
append the end state of the insert job to the list previously created
print the list of job statuses us upon workflow completion
BigQuery has auto-detected the column types and loaded the data.
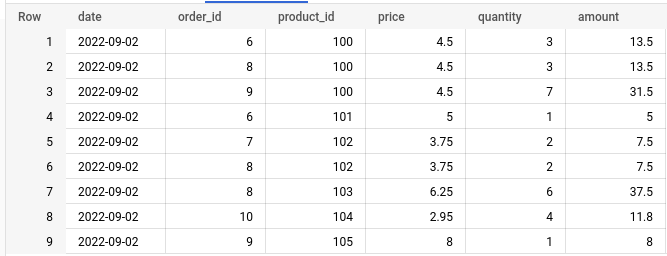
If we were to choose to provide the schema to the job, we can do the following:
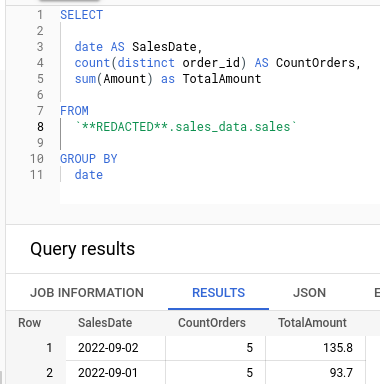
Upon execution, this produces the following result.
What if we have a slightly more advanced use case, and would like to read hundreds of files, which can be quite big, into a partitioned table? The code could look something like the one below.
Notice the following:
timePartitioning by “DAY” based on field date
the sourceUris now has a wildcard “*” to catch all the files ending in “_orders.csv”.
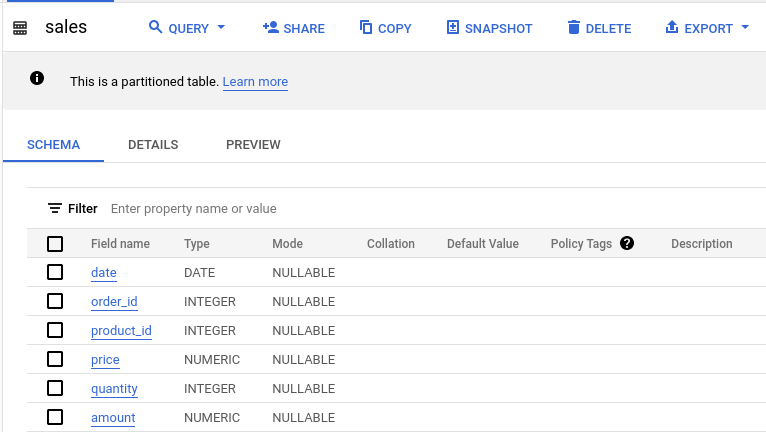
We now have a partitioned table
Conclusion
As we have seen in this exercise, loading data from Google Cloud Storage into BigQuery using Cloud Workflows is quite straightforward and allows us to leverage the BQ API to build repeatable and low-overhead data pipelines in Google Cloud. Thanks for reading!
Found it useful? Subscribe to my Analytics newsletter at notjustsql.com.
Enjoyed this? Here are some related articles you might find useful:




