
Why partitioning tables is not a silver bullet for BigQuery performance

Senior Data Engineer • Contractor / Freelancer • GCP & AWS Certified
I recently encountered an interesting case that reminded me of a couple of things and taught me a few lessons.
When working with BigQuery tables, partitioning and clustering are often go-to operations. Typically, we would partition by a meaningful date (which helps with joins and watermarking in incremental loads) and cluster by columns that form part of the grain, common filters or are commonly used in joins (or within MERGE statements).
While working on a recent task, I had a hypothesis that didn’t quite pan out as expected. Here’s the scenario:
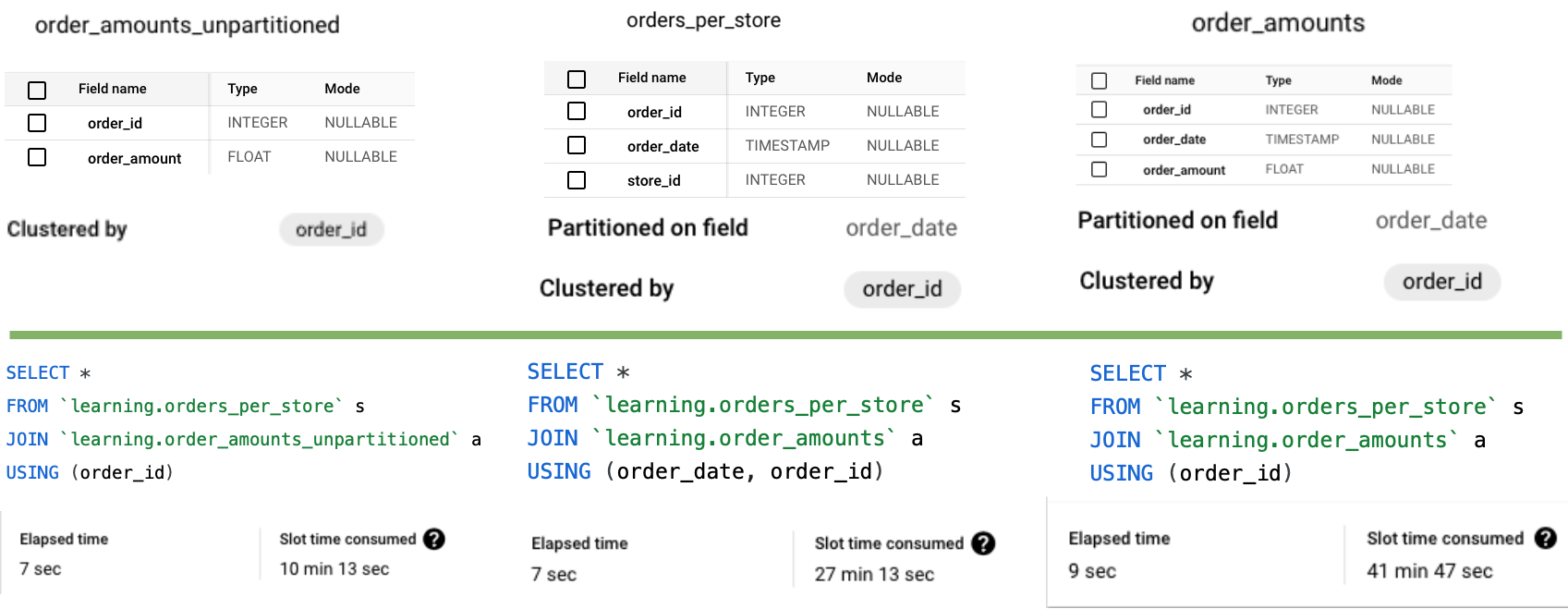
Let's say have two tables:
- orders_per_store, containing fields like order_id, order_date, and store_id.
- order_amounts_unpartitioned, which holds order amounts but is unpartitioned and clustered only on order_id. It doesn’t have any date field.
Since order_id is a unique identifier, it's sufficient for joining. However, I hypothesized that transforming the order_amounts_unpartitioned table to a partitioned one using order_date could improve performance. The idea was to leverage the same order_date field for partitioning in both tables to optimize the join.
To test this, I ran an experiment in my sandbox project with ~5M orders. The results surprised me.
Results:
- The join with the original unpartitioned table (order_amounts_unpartitioned), clustered by order_id, actually performed best in terms of cost and efficiency when joined on just order_id.
- Contrary to my assumption, the option I thought would be more efficient—joining by both order_date (the partitioning field) and order_id—was significantly more costly.
- Lastly, joining with the partitioned table but using only order_id — proved to be least efficient.
Key Takeaway: This served as a great reminder: clustering alone is often enough (and the best solution) to optimize query performance, especially when partitioning results in small partitions (the docs recommend at least 10 GB per partition!).
Partitioning by default isn’t always the best approach—particularly for smaller tables— so consider clustering carefully, including the order of clustered fields.
Ultimately, this reinforced the importance of validating assumptions through real-world testing.
The resource consumption varied significantly across runs (so avoid thinking in terms of precise percentages), but the relative performance rankings remained consistent. It should be also noted that these results might be different based on the querying patterns and needs.
Found it useful? Subscribe to my Analytics newsletter at notjustsql.com.
Enjoyed this? Here are some related articles you might find useful:




