
For quality work, understand your data grain first
Senior Data Engineer • Contractor / Freelancer • GCP & AWS Certified
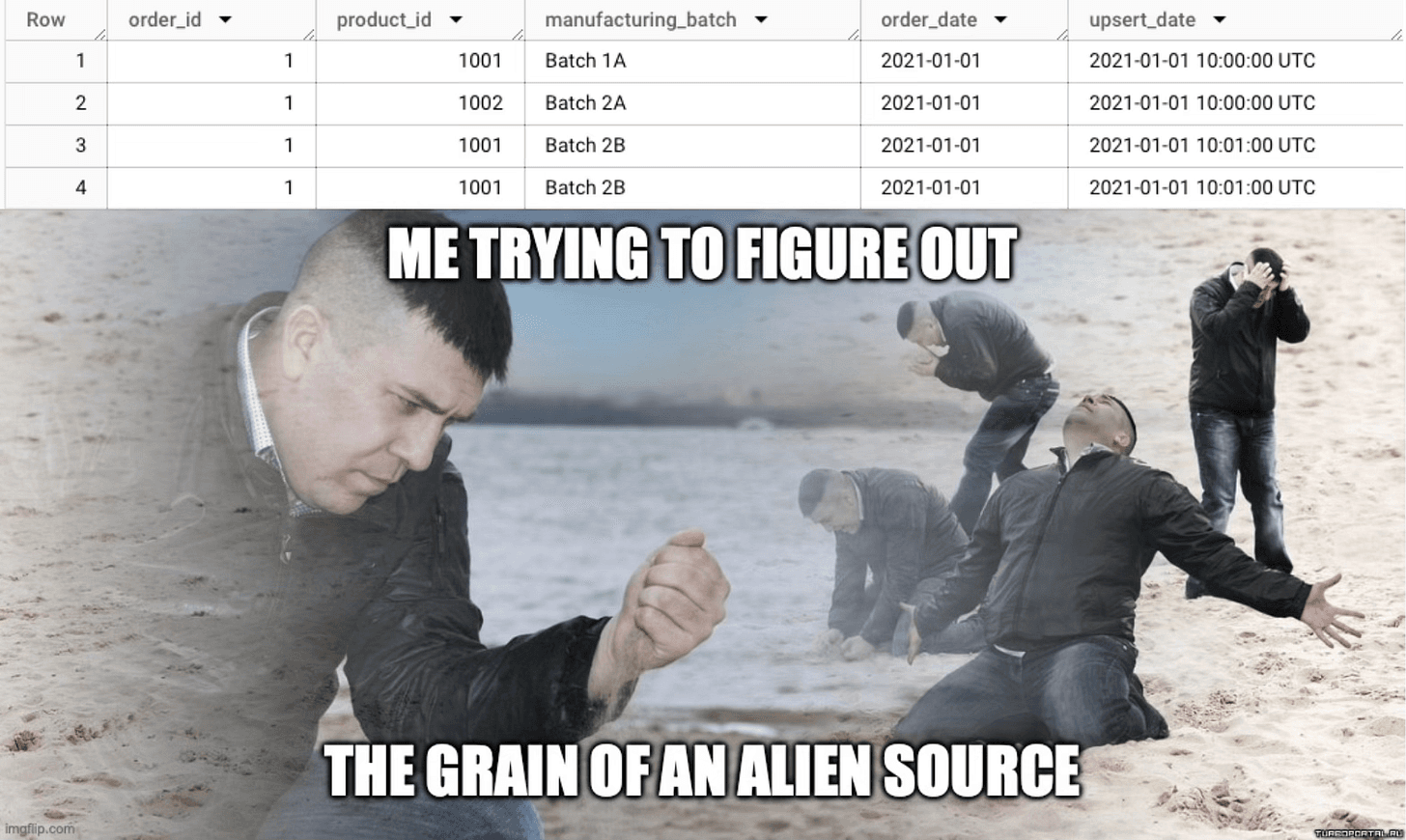
There’s one concept that is central when working with data and goes beyond specific technology or SQL dialects. You just can’t miss it. I’m talking about the grain—the granularity of the data.
It’s essentially answering the question: what does one row of this data represent? Is it an order, a line item in an order, or a status update for a line item?
Thanks for reading Not just SQL! Subscribe for free to receive new posts and support my work.
Subscribed
This is so important because you need to know it to query and ETL data correctly. If not, you’ll end up guessing, and might never be 100% sure you made the right choice. Misunderstanding the grain of a table is how you get faulty joins and duplicates—and why DISTINCT is often slapped on indiscriminately to try and fix the problem.
You need to understand the grain to know whether you should COUNT or COUNT DISTINCT, and whether it’s safe to SUM or JOIN data.
Now, if you’ve ever tried to figure out the grain of an external data source with no documentation, you know it can get tricky. Here’s my approach:
➡️ Of course, find out who maintains the data, get your answers, and give feedback on any issues you find. Then ask for documentation or, in extremis, write down your findings. The next person will thank you!
➡️ If that doesn’t work, start with assumptions based on the columns but test to validate or invalidate what you think is true.
➡️ Iterate fast.
➡️ If you see DISTINCT on anything with more than a couple of columns, run the other way, catch your breath, and return to replace them a methodical approach to duplication.
➡️ Leverage ranking functions like ROW_NUMBER() and DENSE_RANK().
➡️ Use COUNT(1) and GROUP BY to test your hypothesis.
➡️ ????
➡️ PROFIT.
Found it useful? Subscribe to my Analytics newsletter at https://www.notjustsql.com .
Enjoyed this? Here are some related articles you might find useful:




